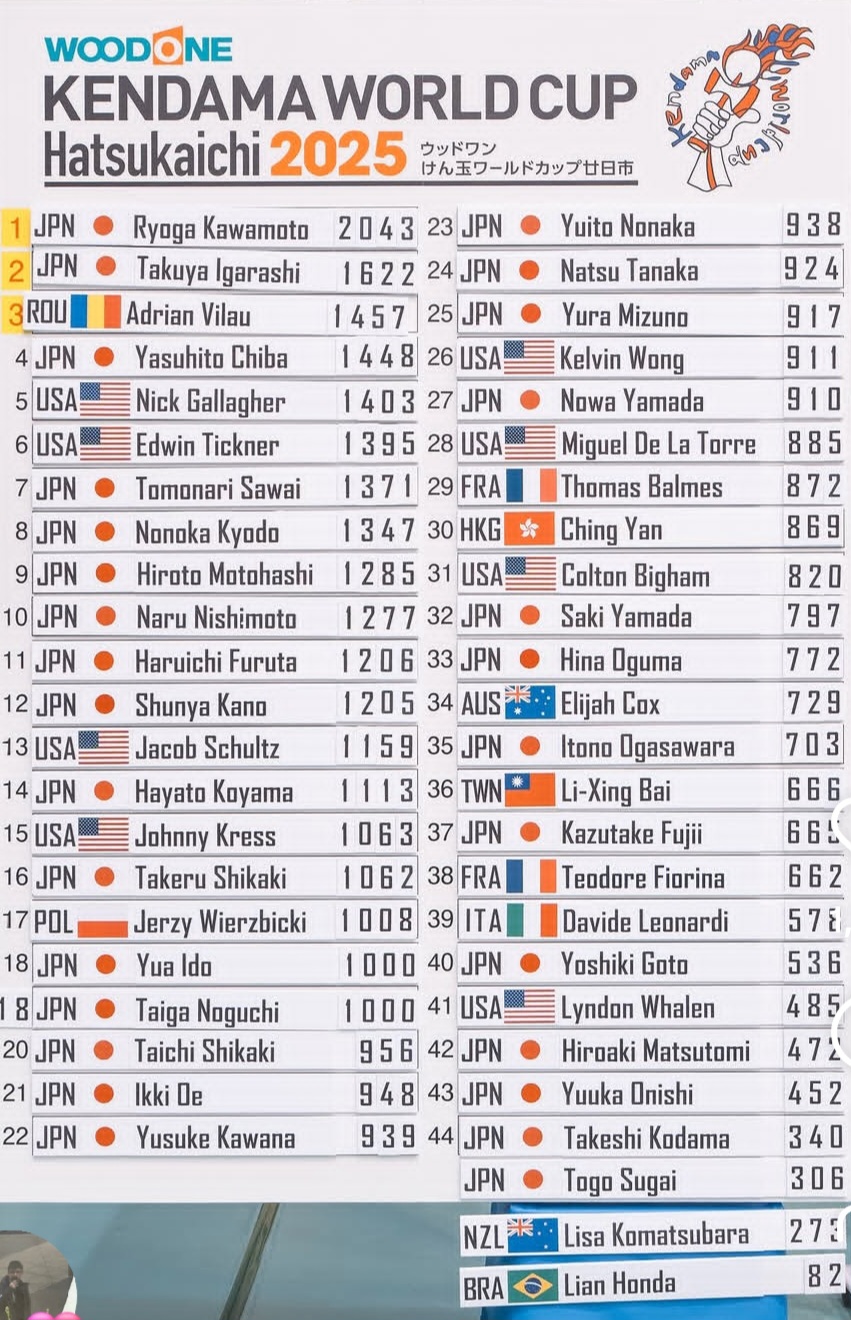
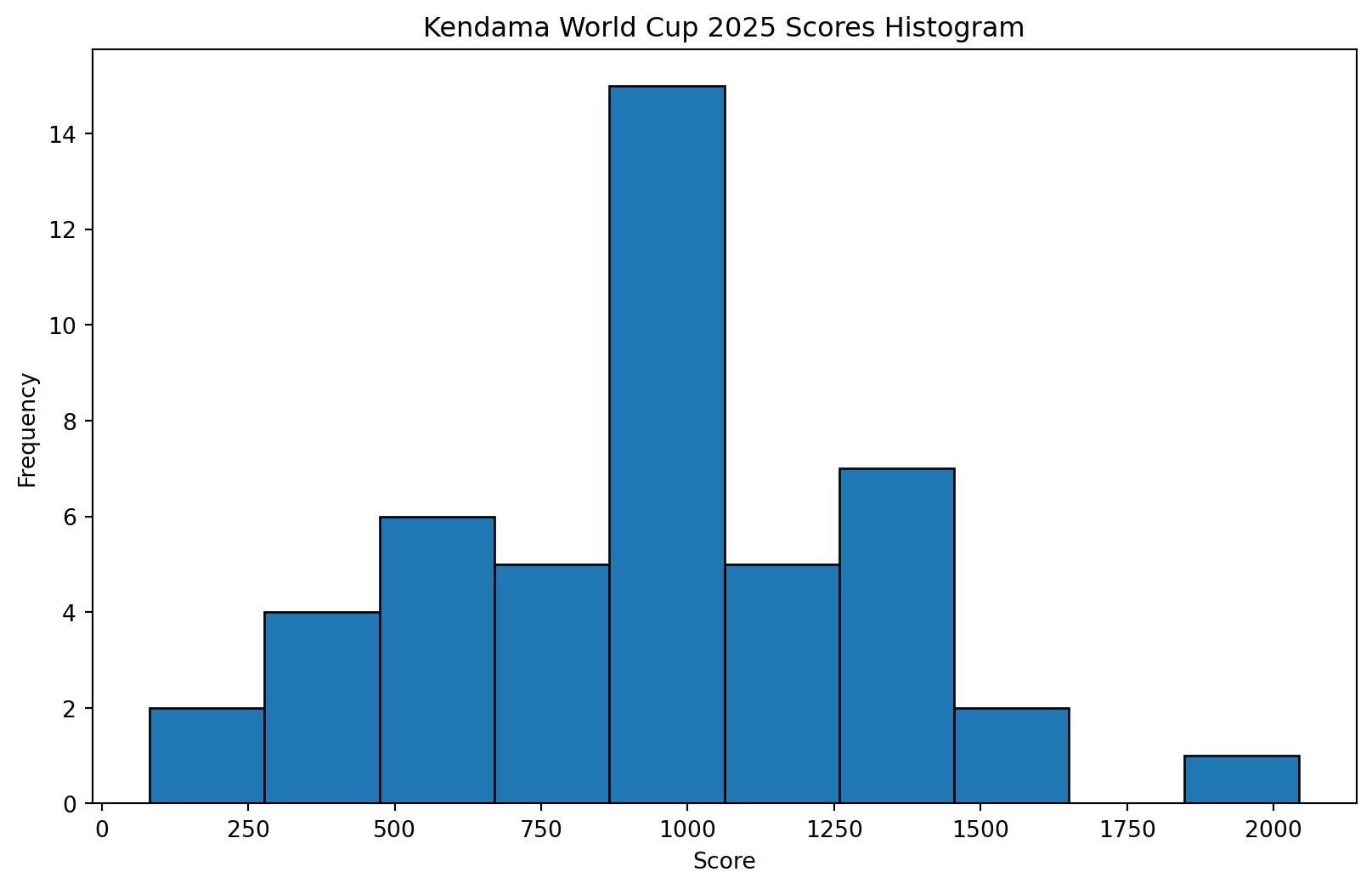
To my surprise the distribution looks bell-shaped, with a very obvious peak at 1000! So while the table form is useful to look up player names and scores, the histogram is even more insightful. I did not expect scores from a competition to also be distributed with such a familar shape. What steps can I take next to see if the scores are normally distributed? Can I apply Central Limit Theorem to make any inferences?